
The EU Is Making AI Watermarks Mandatory. I Removed One Before Lunch.
November 2, 2026 is the deadline. I tested OpenAI's C2PA and Google's SynthID. Both broke before lunch.

A company needs to prove in court that an image wasn’t AI-generated. The official OpenAI watermark is right there: signed, verifiable, timestamped. Then the opposing lawyer asks one question: did the file go through a screenshot before it was sent? The cryptographic chain broke at that exact moment. The proof is gone.
TL;DR
Cause: the European Parliament approved the amendment on March 26, 2026, and the EU Council signed a provisional agreement on May 7. Effect: AI watermarking becomes legally mandatory on November 2, 2026, with fines up to €15 million or 3% of global annual turnover.
Cause: OpenAI’s C2PA watermark lives in the file’s metadata, not in the image itself. Effect: a screenshot destroys the entire cryptographic chain in three clicks, for free, with zero technical expertise. The official verification site doesn’t say “no watermark found”: it crashes with a system error.
Cause: anyone who publishes AI-generated content with human editorial review is explicitly exempt by law. Effect: for most professionals reading this newsletter, the AI disclosure is an editorial choice, not a legal obligation.
Picture the scene. A legal office, 2027. A company needs to prove that an image in circulation was not created with artificial intelligence tools. The document has everything: the C2PA watermark issued by OpenAI, the cryptographic signature, the precise timestamp. The opposing lawyer asks one question: “Is this the original file, or did someone take a screenshot before attaching it to the email?”
Silence.
The answer is no. Someone, before sending it, had pressed Win+Shift+S. In that moment, the cryptographic block tying the image to its origin dissolved. The file that reached the lawyer had no identity left. It was a new file, born from a screenshot, with no history, no signature, no past.
This is where everything that follows begins. Not a sophisticated attack. Not a security expert with laboratory equipment. Three clicks. Free. No technical expertise required.
The law is coming: November 2, 2026, and this time it’s final
Article 50 of the EU AI Act has had a turbulent history. The original enforcement date was August 2, 2026. Then on November 19, 2025, the European Commission presented the 7th Digital Omnibus simplification package. The European Parliament approved it on March 26, 2026; the EU Council reached a provisional agreement on the night of May 7, 2026. The new deadline for watermarking and labeling: November 2, 2026. Less than six months away.
The penalties are not symbolic: up to €15 million or 3% of global annual turnover, whichever is higher. For a company like Google, 3% of global revenue is a number that gives even the most seasoned CFOs pause.
The wording of §2 is precise: providers of AI systems, including general-purpose AI systems, that generate synthetic audio, image, video, or text content must ensure that outputs are marked in a machine-readable format and detectable as artificially generated. Not a recommendation. An obligation with a fine attached.
The key detail: the people who drafted this regulation already know a single approach won’t be enough. The second draft of the Code of Practice, expected to be finalized in June 2026, explicitly acknowledges that “No single active marking technique suffices” and calls for a multi-layer approach: metadata, watermarking, and centralized logging or fingerprinting. The regulator understands the problem. The question is whether the chosen solution can actually deliver.
Who’s doing what today: the industry map
Before getting to the tests, it’s worth mapping the current landscape. It’s far more fragmented than it looks.
Google is the clear leader. Its SynthID system, developed by DeepMind, has already been applied to over 10 billion pieces of content. It covers images generated with Imagen and Gemini, audio from Lyria, video from Veo 3, and even text from Gemini. On the text front, Google is the only operator worldwide with a system in production: OpenAI developed its own text watermarking system but deliberately chose not to release it.
OpenAI opted for the C2PA standard (ISO/IEC 22144, ratified in 2025) for images. GPT-image-2, released on April 21, 2026, implements this standard, as documented in OpenAI’s Help Center. Adobe uses C2PA with its Content Credentials in Firefly and Photoshop. Microsoft integrated C2PA metadata into Designer and Paint. Meta developed Stable Signature for images and AudioSeal for audio.
Then there’s everyone else. An empirical analysis of 50 of the most widely used AI systems found that only 38% implement watermarking adequately, and only 8% have specific deepfake labeling. That means 62% of the most widely deployed systems on the market have nothing real, or something so marginal it doesn’t count as genuine protection. This is five months before the deadline.
The demonstration: I did what anyone could do
The C2PA case: three clicks, watermark gone
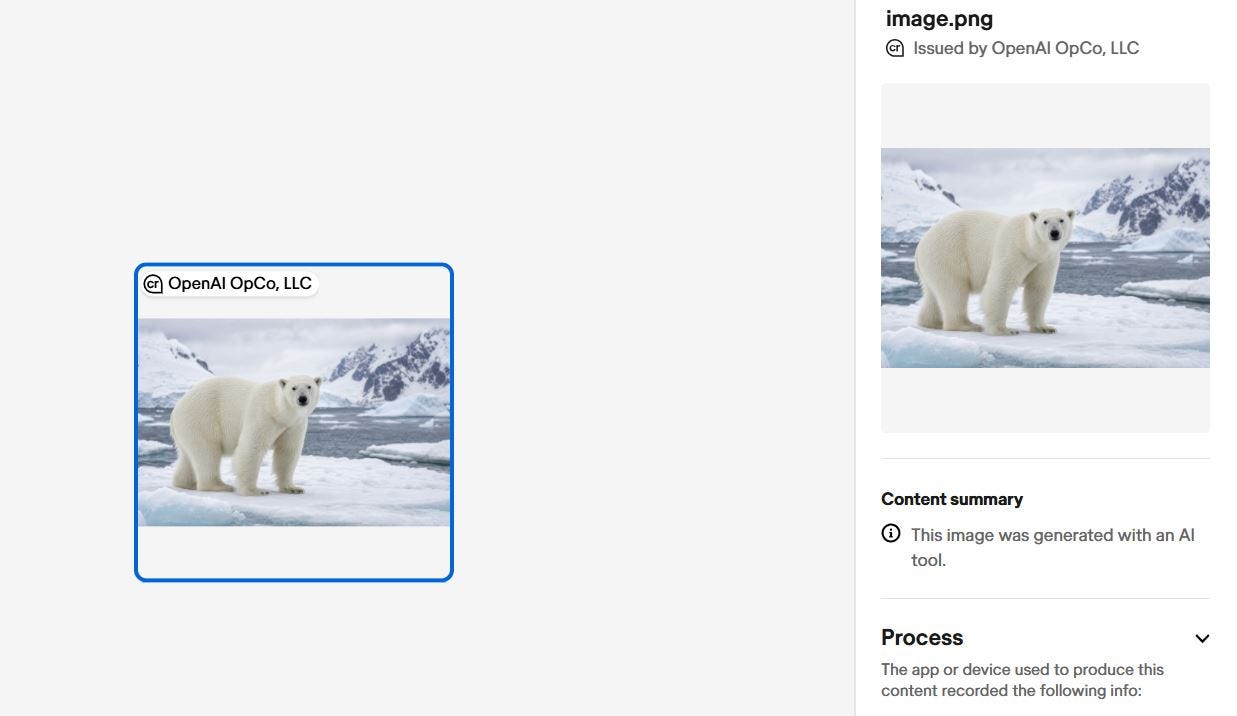
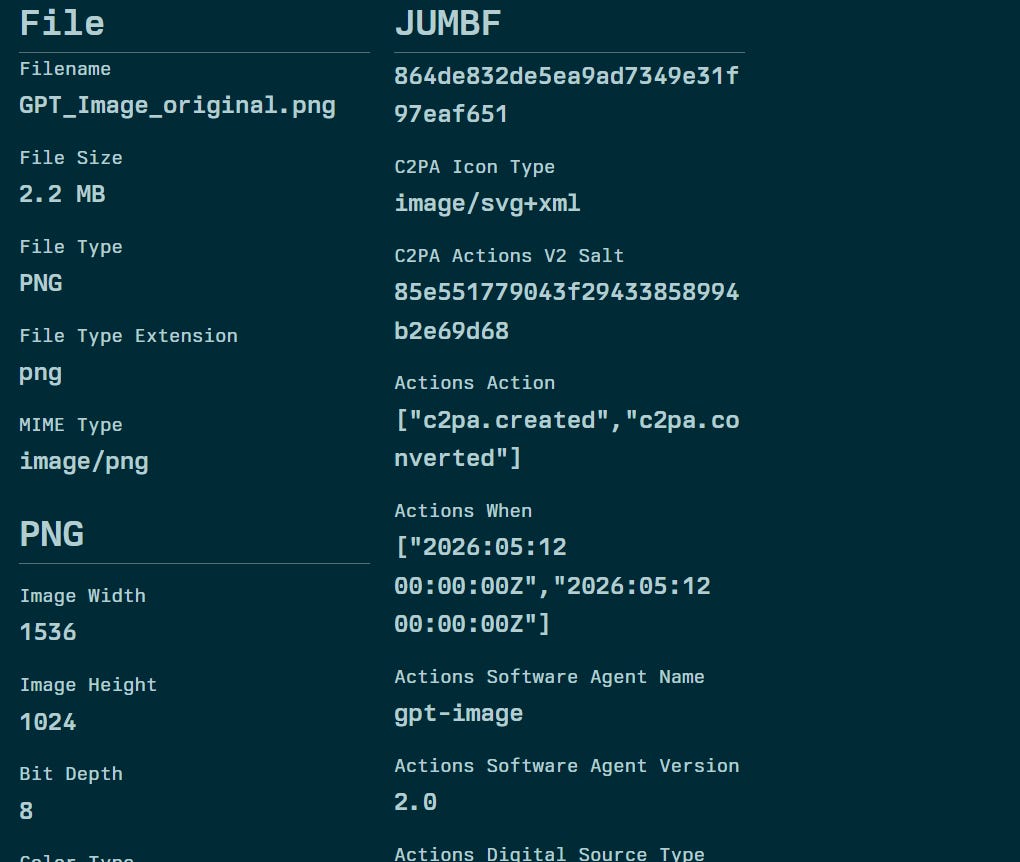
On May 12, 2026, I generated an image with GPT-image-2 via ChatGPT: a polar bear on ice, 1536x1024 pixels, 2.2MB PNG. I then verified the file on contentcredentials.org, the official verification portal of the C2PA consortium.
The result was exactly what you’d expect: C2PA watermark present, issued by OpenAI OpCo LLC, with the statement “This image was generated with an AI tool.” Raw metadata, analyzed with an EXIF reader, showed the JUMBF block with the C2PA cryptographic signature, the recorded actions (”c2pa.created”, “c2pa.converted”), the software agent name (”gpt-image”), version (”2.0”), and the timestamp 2026-05-12.
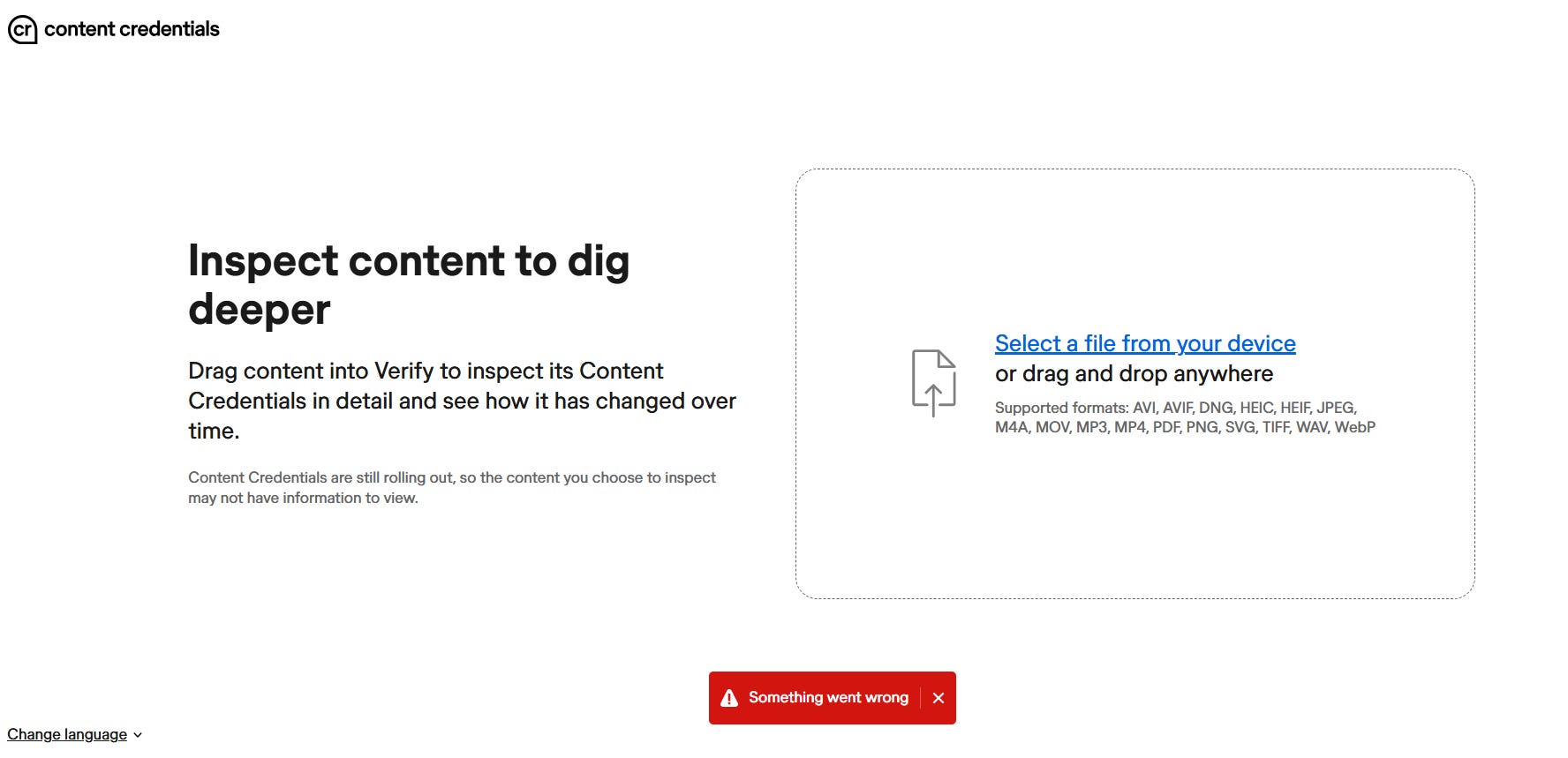
Then I took a screenshot of the image with Win+Shift+S and saved it as a JPG. The new file weighed 121KB, dimensions 1367x768 pixels. I re-verified on contentcredentials.org.
The site’s response? “Something went wrong.”
Not “No Content Credentials found.” Not “Watermark absent.” A system error. The official C2PA verification portal didn’t know how to handle a file without credentials. Instead of returning a clear message, it crashed.
The raw metadata of the screenshot confirmed it unambiguously: no JUMBF block, no C2PA signature, just standard JFIF and EXIF headers. The “Creator” field read: DELL. Not OpenAI. Not GPT-image-2. The device on which the screenshot was taken.
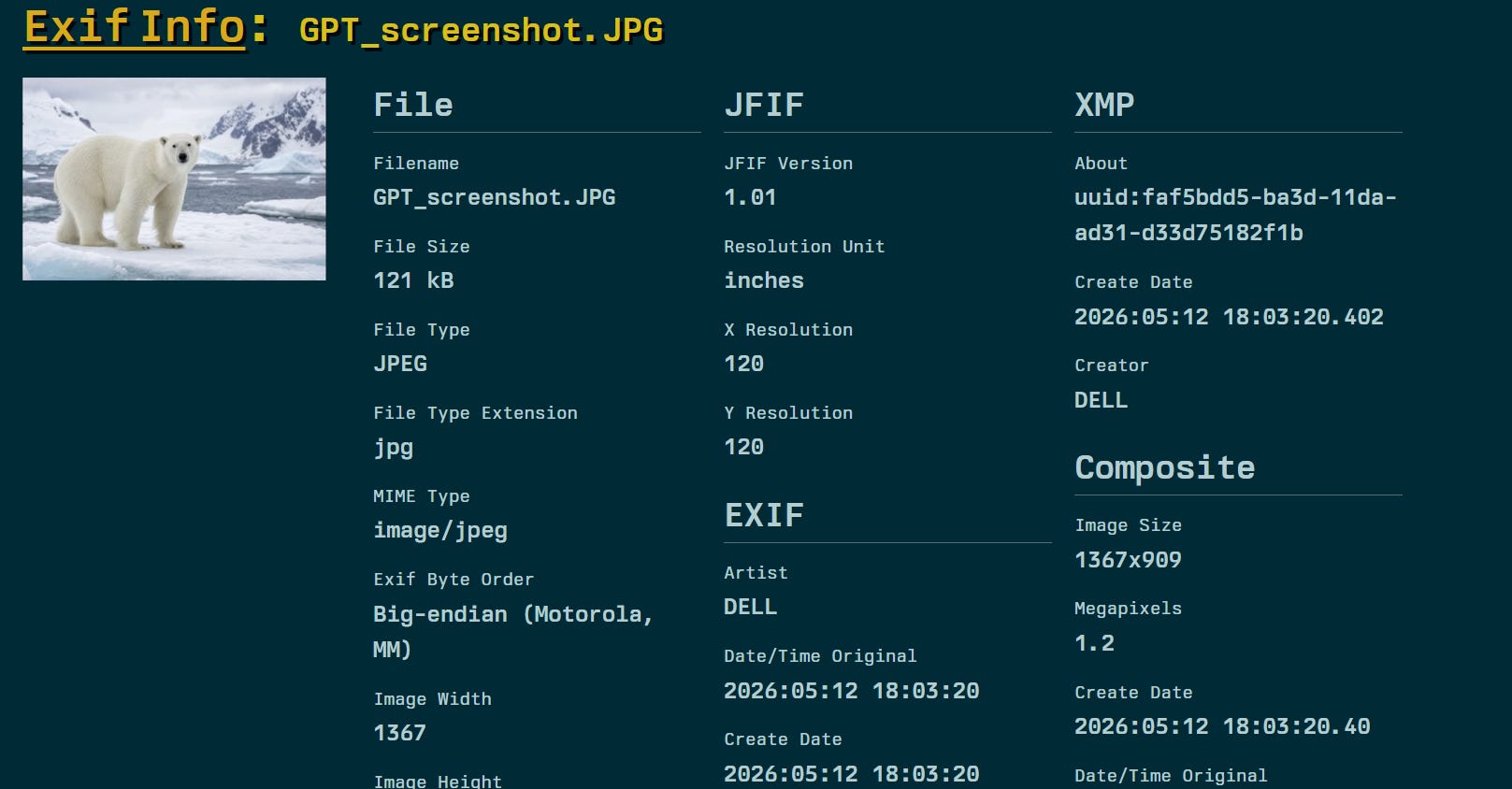
The screenshot had literally rewritten the identity of the file. The workflow, going forward, for anyone who wants to strip a C2PA watermark: generate, screenshot, share. Three steps. Cost: zero. Skills required: zero.
The official C2PA verification portal doesn’t respond “no watermark found.” It responds “Something went wrong.” The verification infrastructure is not designed to handle the most common baseline case: a file that has no credentials.
The SynthID case: the verifier you can’t use
Google built the most advanced system on the market. SynthID has already been applied to over 10 billion pieces of content, covers four different formats, and uses a steganographic technique: the watermark is not in the metadata but embedded directly in the pixels of the image. Removing it is not as simple as taking a screenshot.
And this is where the most structurally grotesque paradox of the entire situation emerges. The SynthID Detector, the public verification portal developed by Google DeepMind, is not public. It’s available via waitlist, reserved for journalists, researchers, and professional media operators. Launched on May 20, 2025, it’s still in early access as of May 2026. There is no publicly accessible URL.
To verify whether an image generated with Gemini actually has a SynthID watermark, an ordinary person must ask Gemini. That is: ask the AI that created the content whether the content is artificial. The law comes into force on November 2, 2026. The verifier is on a waitlist. Did anyone think about the verification infrastructure, or just the production obligation?
I generated the same scene, a polar bear on ice, using Gemini via Imagen: 1408x768 pixels, 2.2MB PNG. To verify the presence of the SynthID watermark, I uploaded the image directly to Gemini and asked: “Is this image AI generated? Does it contain a SynthID watermark?” Gemini’s response: “Based on a SynthID check, this image was generated or edited with Google AI.” Watermark confirmed.
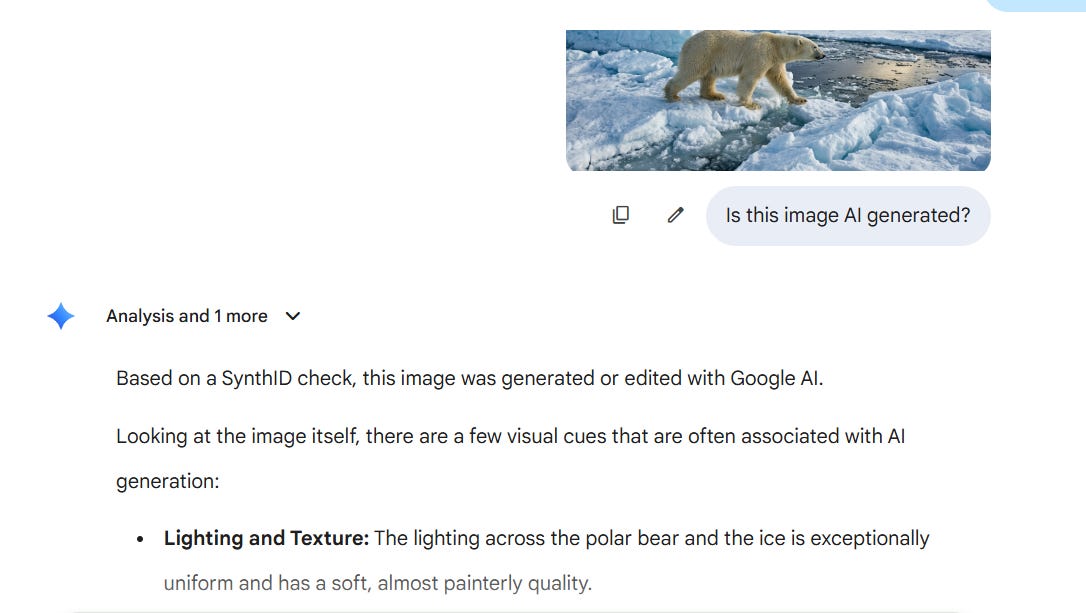
On the removal front, I ran the open source tool remove-ai-watermarks v0.3.4. The AI metadata stripping completed successfully. The invisible steganographic watermark, the one embedded in the pixels, required a dedicated GPU that wasn’t available for the test, so that phase was skipped.
The scientifically relevant data, however, doesn’t come from my test. It comes from research published in April 2026 and documented in the Synthid-Bypass repository on GitHub, which reached 1,600+ stars in just a few weeks. Researchers demonstrated bypass via 2D Fourier transform and phase coherence analysis. No machine learning. Pure mathematics, available in any standard scientific library. Results: 91% removal of watermark energy, with image quality intact, measured at PSNR 43.5 dB and SSIM 0.997. In visual terms: the image remains identical to the human eye, but the watermark is gone.
The problem is not a bug: it’s a design trade-off
Here it’s important to be precise, because the temptation to “blame Google” or “blame OpenAI” leads us astray.
For a watermark to work in practice, it must be invisible and non-invasive. If you can see it, no one will accept it because it degrades the content’s quality. But the more hidden and lightweight it is, the more fragile it becomes. Any operation that modifies the pixels of an image, a screenshot, compression, a crop, an Instagram filter, or that strips file metadata, destroys or weakens the signature. The most robust watermark degrades the image. The watermark that doesn’t degrade the image is fragile. This isn’t a bug. It’s the physics of the problem, a technical trade-off that no engineer at OpenAI or Google can resolve simply by increasing the R&D budget.
The regulator chose the tool that works best in the lab and breaks first in the real world. Not out of bad faith, but because watermarking was the most visible and immediate solution, the one that gives the impression of having addressed the problem.
The surprise: who is actually obligated by the law
There is an element of Article 50 that gets systematically overlooked in public debate, and which radically changes the picture for most readers of this newsletter.
Paragraph §2 obligates the providers of AI systems, meaning Anthropic, Google, OpenAI. They must mark their outputs. Not the end user.
Paragraph §4 concerns deployers, those who publish AI-generated text content on matters of public interest. But it contains an explicit exemption, written directly into the regulatory text: anyone who submits the content to human editorial review, and where a natural or legal person has editorial responsibility for the publication, is exempt.
Anyone who chooses the angle of a piece, edits the text, adds original data, reviews and approves the publication: has editorial responsibility. The law precisely distinguishes between those who use AI as an editorial tool and those who publish raw outputs automatically, without any human intervention in the process. The exemption was written specifically to encode this distinction.
For virtually everyone who reads this newsletter: no legal disclaimer obligation. Transparency remains a sound practice and a sign of respect for your audience. But it is not a legal obligation. It is an editorial choice.
If you run a business publishing AI content automatically, without human review in the workflow, auditing your AI stack before November becomes urgent.
Reality Check. AI watermarking is not a security tool. It’s a responsibility signal that works as long as everyone behaves correctly, which is to say: never, in the real world. Formal compliance with Art.50 is not equivalent to real transparency. It’s equivalent to being able to say “we had it in place” in front of a judge. A system that breaks with a screenshot protects no one. And a verifier on a waitlist is not public infrastructure: it’s a lab demonstration with a VIP guest list.
Want to understand how AI can actually work for your business, beyond the hype? From strategy to implementation, I help companies turn artificial intelligence into real results. Explore my AI Consulting services or reach out directly for a discovery call.
What comes after the wrong question
The question that will dominate the industry in the coming months is: “How do we make watermarks more robust?” It’s the wrong question.
The right question is: what guarantees do we actually want from the regulation, and what tools can genuinely support them?
Alternatives exist and they’re not science fiction. Server-side logging, where providers record which content was generated and when, doesn’t require the file to carry its own signature: the signature lives in the provider’s registry, not in the file as it circulates. Separate ML-based detection systems, trained to recognize patterns characteristic of generative content, don’t depend on a watermark that can be removed with a mathematical formula. Centralized, verifiable registration of AI content, with regulated access for competent authorities, is a different architecture but a structurally more robust one.
These solutions have costs. They require agreements between competing operators. They need governance structures that don’t yet exist. They are politically more complex than “add a watermark and you’re covered.”
November 2, 2026 is not the end of the AI watermarking problem. It’s the date the problem officially becomes visible to everyone. Including judges.
I think it's good there's some regulation around AI. Frankly the world is late.